釘釘聯手通義推出Fun-ASR語音識別大模型
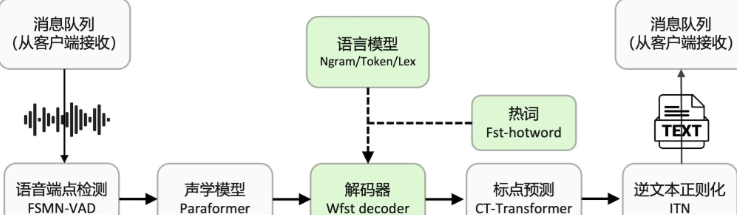
語音識別技術迎來重大突破!釘釘聯合通義實驗室語音團隊,發布了新一代語音識別大模型 Fun-ASR。這款模型可將各種語音信號準確轉寫為文本,具備強大的多行業術語識別能力,不同語言、口音都難不倒它。同時,企業還能根據自身需求,定制專屬模型,全面提升語音交互的效率與精準度 。

釘釘聯手通義推出Fun-ASR語音識別大模型
釘釘與通義實驗室語音團隊今日宣布,雙方聯手推出新一代語音識別大模型 Fun-ASR。這款模型旨在為企業用戶提供更強大、更靈活的語音轉寫能力。

Fun-ASR 大模型具備多項核心優勢。首先,它能夠高效轉寫各種復雜的語音信號,并能精準識別多種行業術語,有效提升了在專業領域的應用準確性。此外,該模型還支持不同語言和口音的識別,極大地拓展了其應用場景。
針對企業的個性化需求,Fun-ASR 提供了專屬模型定制訓練服務,允許企業根據自身業務特點和術語庫進行深度優化,從而獲得更契合業務場景的語音識別能力。
此次合作的 Fun-ASR 大模型,標志著釘釘在企業協作工具的智能化道路上邁出了堅實的一步,為企業提供了更加高效、智能的語音交互解決方案。
據介紹,目前,Fun-ASR的潛力尚未被窮盡,雙方將繼續探索在方言識別、噪聲魯棒性、多語種支持及企業深度定制等方向的升級工作,不斷提升語音轉寫的精準度和實用性,為更多企業業務場景的智能升級賦能。
Funasr大模型簡介
Funasr是阿里云推出的一款基于深度學習的語音識別大模型,具備優秀的識別準確率和實時性能。模型支持多種語言的語音到文本的轉換任務,并且能夠在復雜噪聲環境下保持穩定的識別效果。
本地部署的關鍵步驟
環境準備:首先,需要搭建一個適合深度學習模型運行的環境,包括高性能的計算資源、充足的存儲空間和穩定的網絡環境。
模型下載與優化:從阿里云官方渠道下載Funasr大模型的預訓練權重。根據實際情況,可以對模型進行微調優化,以適應特定場景的識別需求。
部署平臺選擇:選擇合適的本地部署平臺,例如使用Docker容器技術或者Kubernetes集群管理工具,確保模型的穩定運行和易于管理。
服務接口配置:配置模型的輸入輸出接口,使其能夠接收語音數據并返回識別文本。同時,需要設置合適的服務調用參數,以保證模型的性能和響應時間。
Funasr性能超越Whisper的關鍵因素
算法優化:Funasr在算法層面進行了諸多創新優化,包括更先進的神經網絡結構設計、更有效的訓練策略等。這些優化舉措顯著提升了模型的識別準確率和抗噪聲能力。
數據多樣性:阿里云在構建Funasr大模型時,充分利用了其龐大的數據資源。多樣化的訓練數據使得模型能夠學習到更豐富的語音特征,從而提高了其泛化能力。
硬件加速:阿里云針對其硬件平臺進行了專門的優化,充分利用了硬件的計算資源,實現了高效的模型推理速度。這也是Funasr在本地部署時性能出色的重要原因之一。
應用前景展望
隨著語音識別技術的不斷進步,Funasr大模型作為一款性能卓越的本地部署解決方案,將在多個領域展現出廣闊的應用前景。例如,在智能客服系統中實現高效的語音交互,提升用戶體驗;在自動駕駛領域輔助車輛更準確地理解乘客指令;在醫療領域輔助醫生進行病歷記錄等。
此外,隨著5G和物聯網技術的普及,邊緣計算將成為未來技術發展的重要趨勢。Funasr大模型的本地部署優勢將在這種分布式計算架構中發揮重要作用,為用戶提供更加便捷、高效的語音服務體驗。

-

作為串聯新作的“橋梁”!《巫師3》或許將上線新DLC
瀏覽量:02025-12-13
-
《怪物獵人:荒野》第四彈更新視頻來襲!強大的巨戟龍即將亮相
瀏覽量:02025-12-13
-
《PUBG:黑域撤離》官方預告片釋出 首次封閉測試啟動
瀏覽量:02025-12-13
-
雙屬性怪物來襲!《怪物獵人物語3》解鎖全新“野外孵育”系統
瀏覽量:02025-12-13
-
卡牌構建類寶可夢游戲《Mamon King》上線 火速躥升熱銷榜第一
瀏覽量:02025-12-13
-
2026年《怪物獵人:荒野》的更新路線圖顯示,2月將迎來該作的最終更新
瀏覽量:02025-12-13













